Interpreting Grammar Test Results
Results from tests run in the Grammar Tester are displayed in two places:
- Abbreviated results are displayed in the Summary frame in the main Tester window.
- Full details are given in the Test Report, displayed immediately after tests have finished.
Summary Frame
The main window of the Grammar Tester displays some statistics in the right-hand Summary frame.

Number of Evaluated Calls
The total number of calls that were evaluated.
Number of Evaluated Interactions
The total number of interactions that were evaluated.
Average Conf Score Correct
The average confidence score for correct answers.
Standard Deviation for correct answers
The standard deviation of the confidence scores of correct answers.
Average Conf Score for incorrect answers
The average confidence score for incorrect answers.
Standard Deviation for incorrect answers
The standard deviation of the confidence scores of incorrect answers.
Number of Transcriptions Evaluated
The number of transcripts evaluated for in/out-of-grammar coverage.
In-Grammar Accuracy
The percentage of transcripts correctly represented by the grammar.
Number of Semantics Evaluated
The number of transcripts evaluated for semantic matches.
Semantic Error Rate
The percentage of transcripts that were incorrectly evaluated.
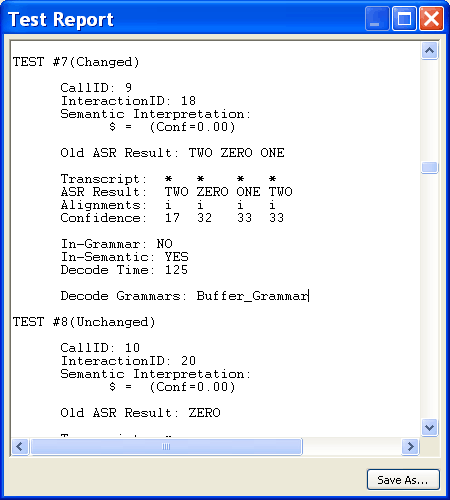
Test Report
The Test Report appears when the Tester finishes its scheduled tests. It can also be seen at any time by selecting View Detailed Report at the bottom of the Summary frame in the Tester window.
Batch Statistics
If you run the Tester in batch mode, i.e. if you test more than one interaction at a time, you will receive additional Summary Statistics that pertain to the entire batch:
-
Word Error Rate
The word-for-word error rate. Lower numbers are better.
-
Avg. Error Confidence
The average confidence score for incorrect tokens.
-
Error Confidence Standard Deviation
The standard deviation for the confidence scores for the incorrect tokens.
-
Avg. Match Confidence
The average confidence score for correct tokens.
-
Match Confidence Standard Deviation
The standard deviation for the confidence scores for the correct tokens.
The Tester will also give you statistics for interactions that had Errors and interactions that were Correct, broken down by alignment (see the list of alignment types). The following statistics are given per alignment:
-
Count
Number of tokens in this alignment.
-
TotalConf
Total confidence score for all tokens in this alignment type.
-
Min Conf
Lowest confidence score of the tokens in this alignment type.
-
Max Conf
Highest confidence score of the tokens in this alignment type.
-
Avg Conf
The average confidence score of the tokens in this alignment type.
-
Standard Deviation
The standard deviation of the confidence scores.
-
In-Vocabulary Count
The number of tokens that were inside the vocabulary.
-
Out-of-Vocabulary Count
The number of tokens that were outside the vocabulary.
Individual Interactions
For each interaction, the Tester will give you detailed information:

-
Test Number
The number of the test, and its status. Changed or Unchanged refers to whether the grammar for that interaction was changed before the test was run, and it will display whether the interpretation is Correct or Incorrect. If the interpretation did not change, it will be listed as Still Correct or Still Incorrect, if it did change it will be listed as Now Incorrect or Now Correct.
-
CallID and InteractionID
The number of the call and the interaction within the call. With these two pieces of data, you can use the Call Browser to locate the specific transaction and see more details about it.
-
Semantic Interpretation
The meaning as interpreted by the speech engine.
-
Old ASR Result
What the speech engine recognized the interaction as before the test.
-
Transcript
What the transcriber entered. An asterisk (*) denotes no transcript.
-
ASR Result
The tokens as recognized by the speech engine under the test conditions.
-
Alignments
Either an insertion, deletion, substitution, match or out-of-vocabulary insertion. See the list of alignment types for more information.
-
Confidence
The confidence score.
-
In-Grammar
Whether or not the interaction was recognized as being in-grammar.
-
In-Semantic
Whether or not the interaction's semantic meaning was understood.
-
Decode Time
The time, in milliseconds, the decode took.